

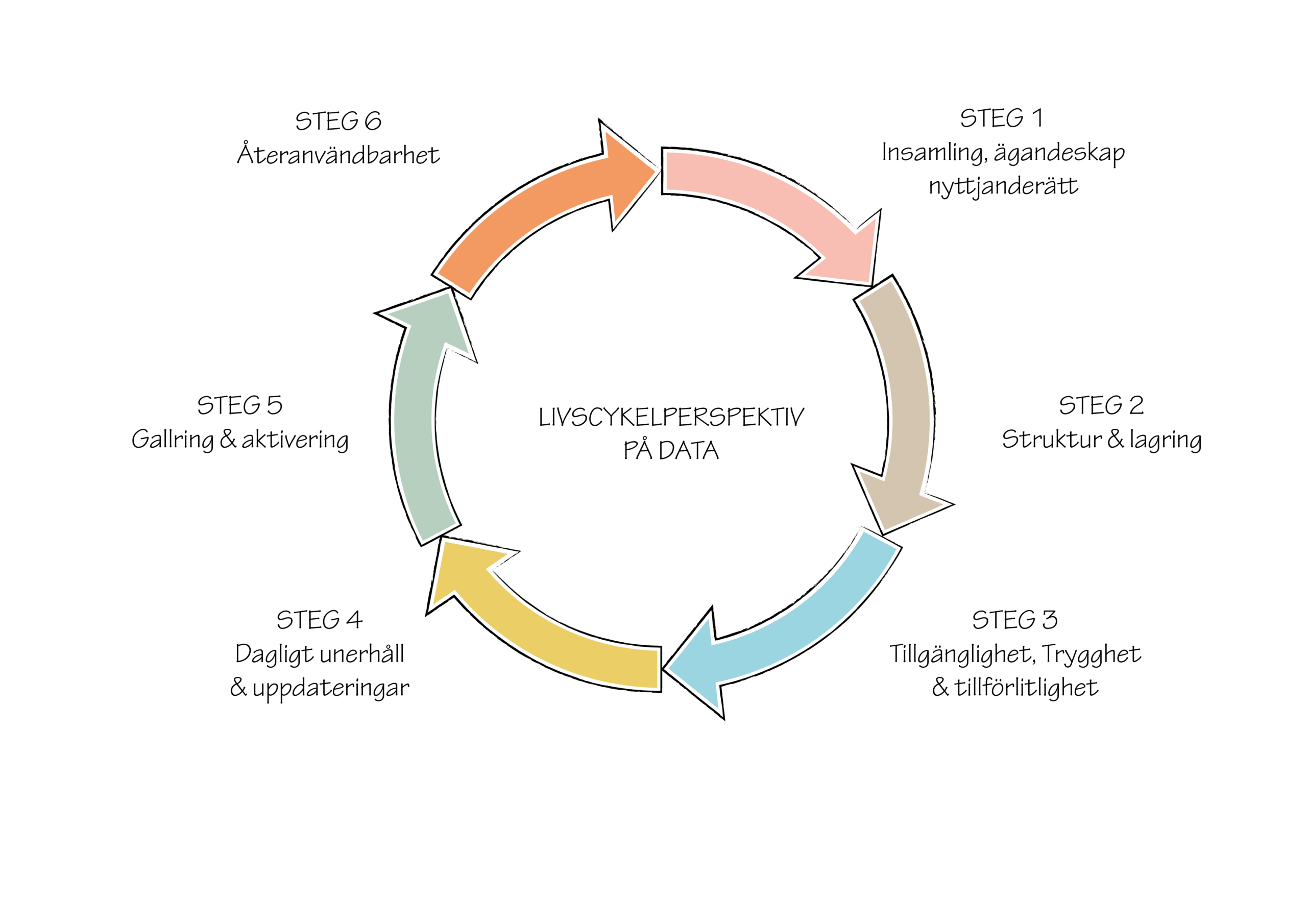
Verktyg: Livscykel för data
Data har en livscykel och behöver kontinuerligt arbetas med för att förbli aktuellt. Förståelse för data i hela livscykelperspektivet lägger grunden för att få rätt processer och rätt resurser på plats för att arbeta strategiskt med data. Projektets expert på dataflöden, Jenny Carlstedt, har tagit fram en vägledning för vad du behöver tänka på genom datans hela livscykel.

- Data förändras över tid
- Olika data behöver hanteras på olika sätt pga skillnader mellan data
- Skapa förståelse för ingående data och arbeta medvetet med data
- Att ta hand om data måste ske kontinuerligt, det är inte en engångsinsats

Experttips
Hitta balansen – djupdyk inte i alla data, ta reda på vad som krävs för att hantera data i AI-lösningen och säkerställ att resurser och tid finns
Om tjänsten är rådgivning – ställ frågor om hur data hanteras till kunden